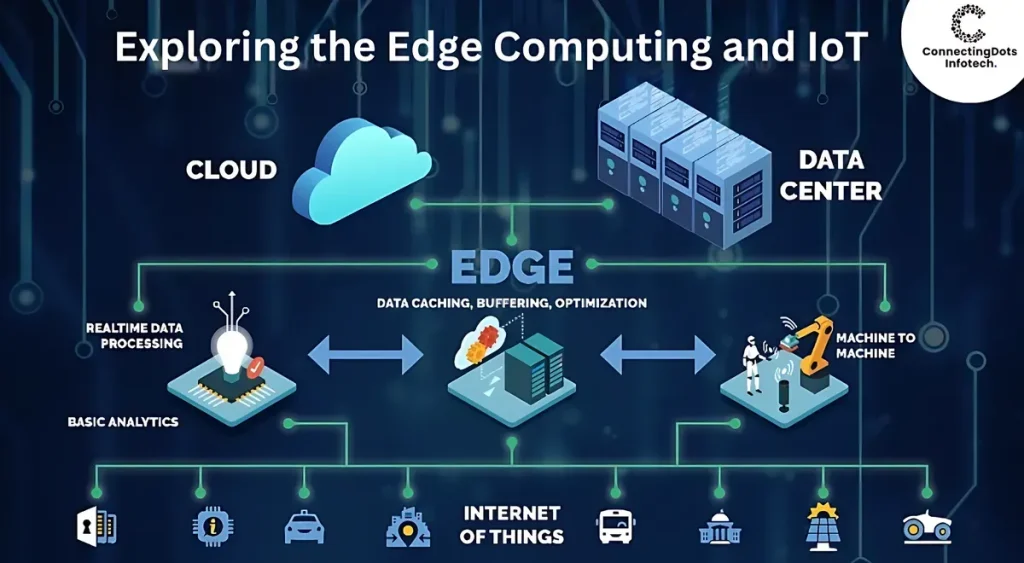
IoT to Edge Computing marks a pivotal shift in how organizations deploy sensing, analysis, and action close to the source. By moving computation from distant data centers to nearby edge nodes, systems gain faster responses and reduced reliance on cloud connectivity. This continuum blends on-device processing with local gateways and edge servers, enabling real-time decisions through IoT data processing in manufacturing, healthcare, and logistics. Including insights from edge computing architecture helps balance latency, bandwidth, and privacy across the stack, including cloud vs edge computing trade-offs. As organizations navigate this edge-driven continuum and compare fog computing vs edge computing, they unlock scalable, resilient architectures for industrial IoT.
From an LSI viewpoint, the shift toward edge-powered models reads as distributed computing at the network edge, not a single upgrade. Think of perimeter or fog-enabled architectures where intelligence moves closer to sensors, enabling rapid analytics without always routing data to the cloud. This framing highlights data locality, privacy, and the ongoing trade-off between on-site decision-making and centralized analytics. Practically, teams can prototype with edge devices, micro data centers, near-edge processing, and lightweight orchestration to deliver resilient, scalable operations.
IoT to Edge Computing: Integrating Edge Architecture for Industrial IoT
IoT to Edge Computing represents a continuum where edge devices, gateways, and micro data centers work in concert with cloud services to process data near its source. This approach emphasizes an edge computing architecture that distributes processing, analytics, and decision-making to the periphery of the network, enabling faster responses, reduced bandwidth, and improved data privacy. In industrial IoT environments, such near‑real‑time processing is critical for monitoring equipment, detecting anomalies, and triggering autonomous actions without delay.
By prioritizing IoT data processing at the edge and in nearby nodes, organizations can achieve resilient operations even with intermittent connectivity. The blended architecture supports selective cloud offloads for long‑term analytics and model training while preserving sensitive data closer to its origin. This balance—edge intelligence feeding cloud-scale insights—aligns with modern technology architectures that accommodate latency, security, and scalability across diverse industrial and manufacturing contexts.
Fog Computing vs Edge Computing: Navigating IoT Data Processing and Cloud Implications
Fog computing introduces a broader, hierarchical paradigm that extends edge capabilities to near‑edge nodes and regional hubs, enabling coordinated IoT data processing across multiple locations. This perspective complements edge computing by providing additional layers for aggregation, filtering, and policy-driven analytics, which can be crucial for large‑scale deployments and industrial IoT use cases. When comparing fog computing vs edge computing, think in terms of proximity to data sources, time sensitivity, and the need for regional context in decision making.
Choosing the right architecture often hinges on latency, bandwidth, regulatory constraints, and required security controls. A hybrid approach can leverage fog computing in regional or campus environments while executing time‑critical workloads at the edge and reserving cloud-based analytics for deep insights and historical trends. By aligning decisions around cloud vs edge computing dynamics, organizations can optimize IoT data processing, support scalable industrial IoT operations, and maintain flexibility as workloads evolve.
Frequently Asked Questions
How does IoT to Edge Computing improve IoT data processing and latency in industrial IoT deployments?
IoT to Edge Computing brings data processing closer to sensors and devices, enabling IoT data processing at the edge rather than sending everything to the cloud. By running analytics, filtering, and decision logic on edge devices or micro data centers, latency drops, network bandwidth is reduced, and privacy is enhanced. This edge-first approach complements cloud-based analytics for long-term storage and model training, supporting industrial IoT use cases like predictive maintenance and real-time monitoring.
What are the key differences between fog computing vs edge computing in an IoT to Edge Computing architecture?
Fog computing vs edge computing describes a broader architectural approach. Edge computing processes data at or near the data source, delivering low latency for time-critical tasks, while fog computing adds a hierarchy of near-edge nodes that aggregate and pre-process data from multiple edge devices. In an IoT to Edge Computing setup, edge devices handle immediate decisions, and fog nodes provide broader analytics and coordination across locations, balancing latency, bandwidth, and reliability.
| Aspect | Key Points |
|---|---|
| Introduction |
|
| Why it matters |
|
| Core components |
|
| Architectural patterns |
|
| Benefits |
|
| Security considerations |
|
| Deployment considerations |
|
| Real-world use cases |
|
| Framework to design |
|
Summary
IoT to Edge Computing marks a broad evolution in technology architectures where compute and intelligence move closer to the data source. This continuum supports edge computing architecture that blends IoT data processing with cloud analytics, including discussions of fog computing vs edge computing and the trade-offs between cloud vs edge computing, especially for industrial IoT use cases. By placing processing near devices, organizations gain lower latency, reduced bandwidth, improved privacy, and greater resilience, while maintaining cloud-scale analytics when appropriate. As AI at the edge, 5G connectivity, and interoperable platforms mature, modern technology architectures will become more capable, secure, and adaptable across industries such as manufacturing, smart cities, healthcare, and logistics.

